IPFS - A protocol for archiving and sharing files

IPFS (InterPlanetary File System) is a P2P (Peer to Peer) protocol that allows for the decentralized distribution of files.
The term “InterPlanetary” highlights the primary goal of IPFS: to overcome the technical difficulties and constraints of communication between planets.
Indeed, when Mars is colonized, the web will need to adapt to allow everyone to access the same internet. While we can display Wikipedia in a few milliseconds on our computers, it will take 4 minutes from Mars under the best conditions and 48 minutes if you are unlucky. These 48 minutes will only be used to display a single page, imagine then for a YouTube video or a series.
This is the precise moment when IPFS comes into play. As it is a file-sharing system between computers that operates without central servers, it will not always be necessary to communicate with an Earth server to read a web page. It will be enough to ask a nearby computer to send the file.
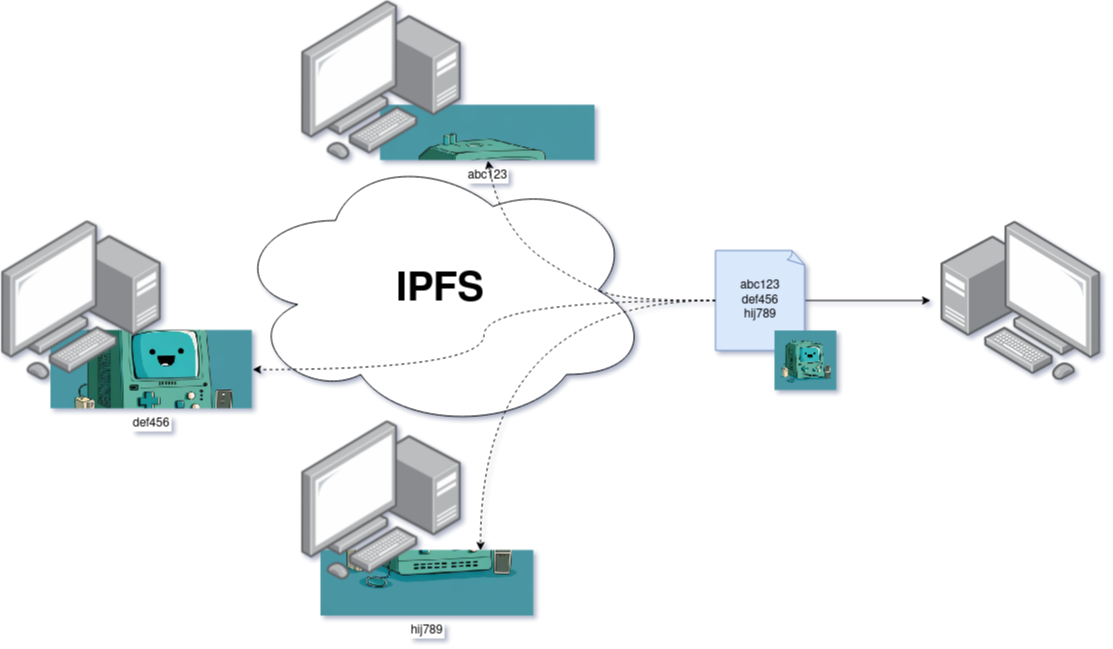
This protocol is a mix between the World Wide Web and BitTorrent, with which the same file can be shared by multiple computers. The IPFS network is therefore a map from which we will request a file (or site) and download it from a server that is not necessarily the server from which the data originates.
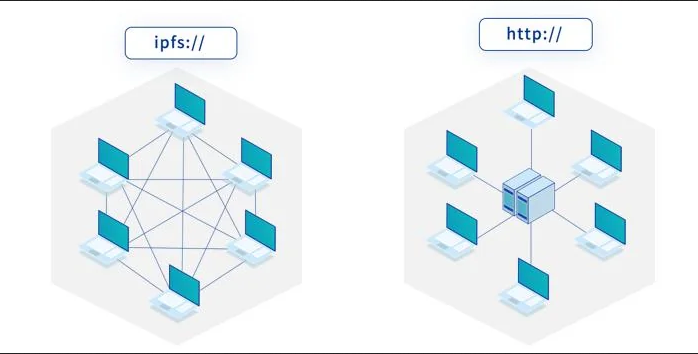
How to access a file?
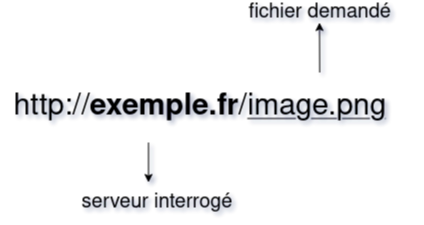
In classic Web, we ask a server for a specific file via a URL that points to a specific file. If we return later: the file may not be the same.
In IPFS, we directly request a file using an identifier based on its content: a CID (Content Identifier), which is a unique hash used to identify your data.
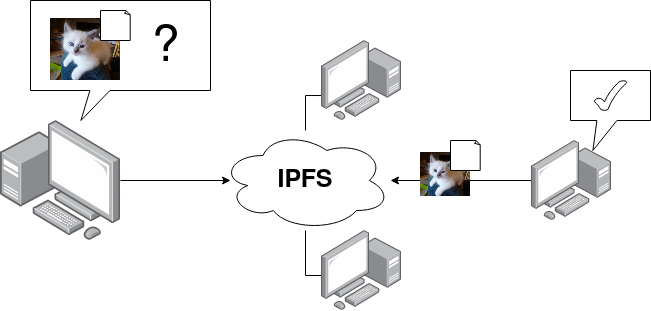
As soon as we upload a file to the IPFS network, we obtain a CID that points to it. This CID is calculated based on the unique fingerprint of the file, and the CID changes if the file is modified.
By reading a file from the IPFS network, we have proof that it is not censored and that it is immutable.
Use Cases
I discovered IPFS through the site Libgen, a search engine for scientific articles. The official site details a bit more about the different reasons to use this network:
- Archiving public data for the long term: IPFS is a reliable way to transmit data to future generations by decentralizing it and giving users who read your data the opportunity to reshare it.
- Hosting a serverless website: From your laptop, you can host a site that will itself be hosted (/reshared) by readers who access your site.
- Sharing large files: IPFS files are split into blocks, allowing you to share large volumes via IPFS and download the blocks in parallel from different servers. (like BitTorrent)
- Making your content uncensorable: Since each file is accessed via a unique hash, you constantly have proof that the file has not been altered by a hacker or an organization.
- Sharing content offline on your network: Sharing can be done without internet access, IPFS clients discover each other (autodiscovery) on a local network and can continue to relay cached files.
File Lifecycle
If I want to send my profile picture into the IPFS network, it will be split into several parts of (maximum) 256 KB each. We then calculate a unique Hash for each piece, and combine them to create the CID of the complete file.
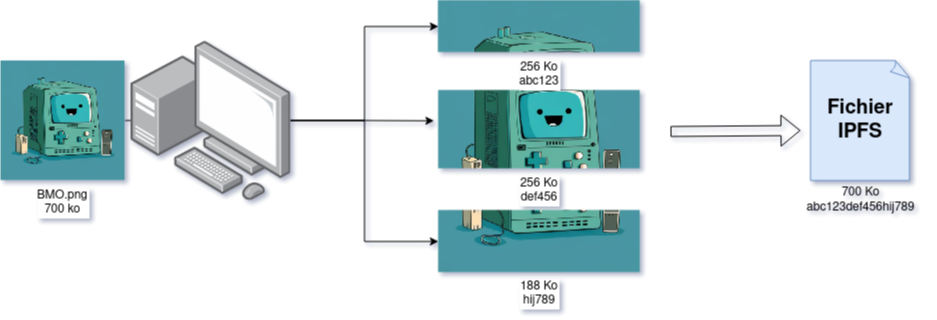
The CID is then an entity that contains the different Hashes of the ~256 KB pieces that allow the original file to be reconstructed.
Splitting a file into multiple blocks allows for deduplication. If I store my image again having only modified the top of the png: I can reuse the identical blocks and only add the difference in IPFS. The CID will still be different (the hash of the first blocks will be modified).
It is therefore possible to reconstruct a complete file by using the parts present in the IPFS network.
Installing an IPFS Client

Kubo is the most well-known and widely used utility for communicating over IPFS. It is written in Golang and can be used via command line or through a web interface.
It installs quite simply:
VERSION="v0.28.0"
wget https://dist.ipfs.tech/kubo/${VERSION}/kubo_${VERSION}_linux-amd64.tar.gz
tar xvfz kubo_${VERSION}_linux-amd64.tar.gz
cd kubo
sudo bash install.sh
As I do not prefer using web interfaces, I will only present the command-line utility. The web interface is available on port 5001 of your machine and does not offer any additional features.
IPFS in Practice
I have two virtual machines on which I have installed Kubo.
The first thing we can do is store a file on the IPFS network. The command is simple: ipfs add <file>. This command will return a CID that corresponds to our file. This CID is unique and allows us to retrieve our file on the IPFS network.
Firstly, each of the machines will have initialized its IPFS client with the ipfs init command. This creates a .ipfs folder in the user directory of the machine.
I create a file hello.txt with the content “Hello!”. The ipfs add utility adds this file to our IPFS node.
# machine 1
➜ ipfs add hello.txt
added QmNURZjTooDCUKjtegXUDF8CeowSN8VLSnPARLGXnxiv11 hello.txt
# machine 2
➜ ipfs cat QmNURZjTooDCUKjtegXUDF8CeowSN8VLSnPARLGXnxiv11
Error: block was not found locally (offline): ipld: could not find QmNURZjTooDCUKjtegXUDF8CeowSN8VLSnPARLGXnxiv11
The reason? It’s simple: Neither of the machines is connected to the IPFS network!
To do this, you need to start the daemon using the ipfs daemon command on both machines.
Once the command is launched, you can read the file on machine 2:
# machine 2
➜ ipfs cat QmNURZjTooDCUKjtegXUDF8CeowSN8VLSnPARLGXnxiv11
Bonjour !
So in this configuration, the hello.txt file is hosted by the IPFS node on machine 1, and accessed by machine 2.
Now, let’s conduct a simple experiment, turn off machine 1, and try to access the file again:
# machine 2
➜ ipfs cat QmNURZjTooDCUKjtegXUDF8CeowSN8VLSnPARLGXnxiv11
Bonjour !
The file is still accessible! This is explained by the existence of a cache on our client. This cache can be configured through the configuration file located at this location ~/.ipfs/config.
...
"Datastore": {
"StorageMax": "10GB",
"StorageGCWatermark": 90,
"GCPeriod": "1h",
...
Or, using the command line:
ipfs config Datastore.StorageMax '"5GB"' --json
We have a maximum cache size of 10GB. The garbage collector will remove this cache once we exceed 90% of the StorageMax.
In addition to allowing the machine 2 to read this file, this cache also serves another purpose.
Let’s add a 3rd virtual machine and try to access the file QmNURZjTooDCUKjtegXUDF8CeowSN8VLSnPARLGXnxiv11. (Knowing that machine 1 is still turned off, it won’t be able to send the file)
# machine 3
➜ ipfs cat QmNURZjTooDCUKjtegXUDF8CeowSN8VLSnPARLGXnxiv11
Bonjour !
The cache allows you to participate in the distribution of this file (without being the initial node).
On the other hand (after deleting the cache on machine 3), if I turn off machine 1 and 2: the file becomes unreachable:
# machine 3
➜ ipfs cat QmNURZjTooDCUKjtegXUDF8CeowSN8VLSnPARLGXnxiv11
(no answer)
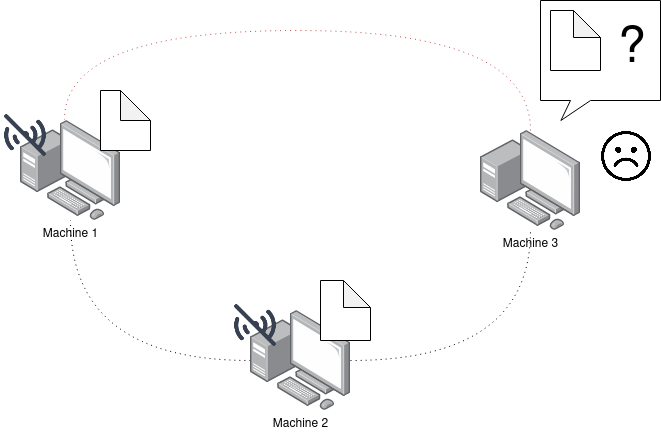
In summary: You always need a machine storing the file on the IPFS network in order to access the data.
But the cache is ephemeral and will be deleted someday! Don’t rely on it to relay your file.
To ask a machine to keep the file and share it, it is necessary to PIN the file.
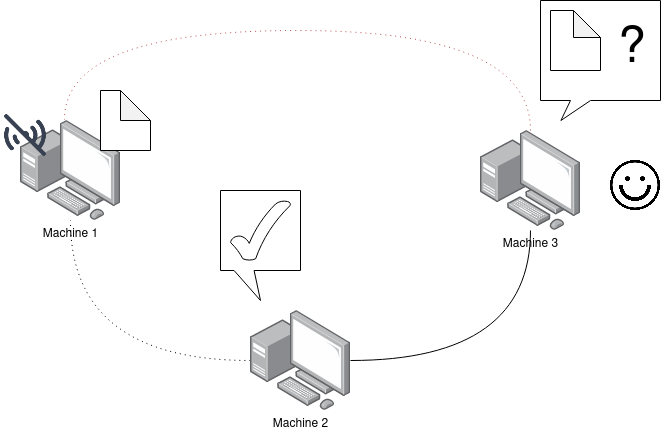
Let’s go back to the initial state: hello.txt on machine 1, and nothing on machine 2 and 3.
We will ask machine 2 to pin our CID so that it is stored outside the cache and becomes persistent on machine 2.
# machine 2
➜ ipfs pin add QmNURZjTooDCUKjtegXUDF8CeowSN8VLSnPARLGXnxiv11
pinned QmNURZjTooDCUKjtegXUDF8CeowSN8VLSnPARLGXnxiv11 recursively
Let’s turn off machine 1 again and try (once again) to read the hello.txt file on machine 3:
# machine 3
➜ ipfs cat QmNURZjTooDCUKjtegXUDF8CeowSN8VLSnPARLGXnxiv11
Bonjour !
The file is now readable as long as machine 1 or machine 2 are on the IPFS network.
Retrieving a file from the IPFS network without a client
There are many public gateways that allow you to access a file from the IPFS network without connecting to a client. The CID of my file is QmNURZjTooDCUKjtegXUDF8CeowSN8VLSnPARLGXnxiv11, and I can read the file from Firefox using this URL: https://ipfs.io/ipfs/QmNURZjTooDCUKjtegXUDF8CeowSN8VLSnPARLGXnxiv11.
If you are using Kubo and have installed the IPFS Companion extension (available here), you will be automatically redirected to your local gateway: http://localhost:8080/ipfs/QmNURZjTooDCUKjtegXUDF8CeowSN8VLSnPARLGXnxiv11
Et puisque nous utilisons notre navigateur… rien ne nous empêche de lire du HTML !
Mon blog étant sous Docusaurus, je vais alors build le site et l’ajouter à mon nœud IPFS:
git clone https://github.com/QJoly/TheBidouilleur.xyz
cd TheBidouilleur.xyz
npm i
npm run build
ipfs add -r ./build
I obtain the CID QmXqrXHXuKB9tHrxUgNphRx8TyKBmtrisuRB2y9FkFta7x and access my website through this URL: http://localhost:8080/ipfs/QmXqrXHXuKB9tHrxUgNphRx8TyKBmtrisuRB2y9FkFta7x or https://ipfs.io/ipfs/QmXqrXHXuKB9tHrxUgNphRx8TyKBmtrisuRB2y9FkFta7x/ (Beware of CSS errors. My Docusaurus doesn’t like not being at the root of the site).
Note that it is not necessary to PIN each element of the folder. It is sufficient to do so only on the root folder of the site (QmXqrXHXuKB9tHrxUgNphRx8TyKBmtrisuRB2y9FkFta7x in my case). The files inside the directory will have an ‘indirect pin’.
➜ ipfs pin add QmXqrXHXuKB9tHrxUgNphRx8TyKBmtrisuRB2y9FkFta7x
pinned QmXqrXHXuKB9tHrxUgNphRx8TyKBmtrisuRB2y9FkFta7x recursively
➜ ipfs pin ls
Qmce2mdHr1ufcGqtnR67DdshJqPCpZ6bSrXxuzQJdga1dy indirect
QmdGAYHsqhxiwNDhkoCR5ryrd74wxGKhcgfsh9NJg5ANqH recursive <-- Un dossier
QmcwA7f9HRwVVMMgJRt4mDbGLbr8jruyGPJxPYmWKhFqs2 indirect
QmednJCZK9SnxAy12rreveUqsMyP7Jfw2Aij1hFGWc3BJu indirect
ipfs.io is a gateway, it is a web-based access that allows you to read a file on the IPFS network. There are many gateways available, and we will see later how to create our own.
Now, the problem with hosting a website on IPFS is that each file is immutable (each entity is accessed using its unique hash). It is not possible to modify your files while keeping the same CID (and therefore changing the access URL), so your users will need to use the new CID to see the latest version of your website.
That’s why there is a solution: InterPlanetary Name System (IPNS).
IPNS allows us to point a URL to a CID, and we can update which CID our IPNS redirects to at any time.
This URL is formed from a key (which allows you to identify yourself on the IPFS network). Whenever you communicate on the network, you use an ed25519 key (check with ipfs key list) named self.
If you want to use multiple IPNS, it is possible to have multiple keys (and therefore obtain multiple ‘domains’), for example:
➜ ipfs key gen --type=rsa --size=2048 mykey
To redirect our IPNS (using the self key) to a CID, we need to use the publish argument:
➜ ipfs name publish /ipfs/QmXqrXHXuKB9tHrxUgNphRx8TyKBmtrisuRB2y9FkFta7x
Published to k51qzi5uqu5dl8idfkamiq22x12pr1rlha4i1izbi2hq5nlv3vuqt7nztq4krf: /ipfs/QmXqrXHXuKB9tHrxUgNphRx8TyKBmtrisuRB2y9FkFta7x
It is also possible to specify the key:
➜ ipfs name publish --key=mykey /ipfs/QmXqrXHXuKB9tHrxUgNphRx8TyKBmtrisuRB2y9FkFta7x
Published to k2k4r8jfpj0rsylz08ahbkar950da3a77wfcreiwh85hnp9op504l0e0: /ipfs/QmXqrXHXuKB9tHrxUgNphRx8TyKBmtrisuRB2y9FkFta7x
Warning
To verify where an IPNS points to, I can perform an equivalent of nslookup using ipns name resolv:
To verify where an IPNS points to, I can perform an equivalent of nslookup using ipns name resolv:
➜ ipfs name resolve k51qzi5uqu5dl8idfkamiq22x12pr1rlha4i1izbi2hq5nlv3vuqt7nztq4krf
/ipfs/QmfEyL1zeaL7fWb6ugfzzh7zzdyyP7zSkb5smAyhttuQKS

Warning
During the writing of this article, no public gateway was able to display my blog using my IPNS.
I had to use my local gateway (localhost:8080) on my machine and host my own gateway for machines that do not have Kubo installed. We will see how to create our gateway below.
Mais retenir par cœur une clé est (légèrement) compliqué, il est alors possible d’utiliser votre propre nom de domaine en tant qu’IPNS. Pour cela, il suffit d’ajouter une entrée TXT à votre nom de domaine:
ipfs.thebidouilleur.xyz. 60 IN TXT "dnslink=/ipfs/QmXqrXHXuKB9tHrxUgNphRx8TyKBmtrisuRB2y9FkFta7x"
➜ ipfs name resolve ipfs.thebidouilleur.xyz
/ipfs/QmfEyL1zeaL7fWb6ugfzzh7zzdyyP7zSkb5smAyhttuQKS
Info
Instead of regularly editing your DNS entry to change the CID, it is also possible to use an IPNS key:
ipfs.thebidouilleur.xyz. 60 IN TXT "dnslink=/ipns/k51qzi5uqu5di2e4jfi570at4g7qnoqx1vwsd2wc0pit1bxgxn22xwsaj5ppfr"
You just need to update which CID this IPNS points to using ipfs name publish.
An instance of my blog is accessible through IPFS:
- With the IPFS browser extension:
ipfs.thebidouilleur.xyz - Through a local gateway:
localhost:8080/ipns/ipfs.thebidouilleur.xyz - Through a public gateway:
ipfs.io/ipns/ipfs.thebidouilleur.xyz(Not functional for me)
Hosting an IPFS Gateway
As explained earlier, I am unable to resolve IPNS through public gateways.
Therefore, I had to create my own gateway:
You just need to initialize your configuration (ipfs init) as shown above and modify it as follows:
➜ ipfs config --bool Swarm.RelayService.Enabled true
➜ ipfs config --bool Swarm.RelayClient.Enabled true
➜ ipfs config AutoNAT.ServiceMode '"enabled"' --json
➜ ipfs config Addresses.Gateway "/ip4/0.0.0.0/tcp/8080"
Once these commands are executed, you can directly retrieve IPFS objects in your browser using the same syntax as other gateways. For example: http://192.168.128.10:8080/ipns/k51qzi5uqu5di2e4jfi570at4g7qnoqx1vwsd2wc0pit1bxgxn22xwsaj5ppfr.
Git Repository on IPFS
While exploring the documentation, I found this page that presents a simple procedure for storing a Git repository in ReadOnly mode.
We then retrieve a repository using the --mirror argument, which allows us to retrieve the repository as compressed objects. (equivalent to the .git folder of a repository)
git clone --mirror https://github.com/qjoly/helm-charts
If (as I just did) you have cloned your repository using HTTPS (and not SSH), you will need to generate auxiliary files using the git update-server-info command. These files generated or updated by git update-server-info are necessary for Git clients to retrieve the objects and references of the repository.
git update-server-info
We now add the cloned folder to our IPFS node:
ipfs add -r ./helm-charts.git
added QmbRUdVtdtxcpdqyJE3iZwTJq7FPcXR1ErQRFB76sQCg9H helm-charts.git/HEAD
added QmWadTGKYEjYf5Y7wKS66fLrTQm3ViH34QFoxbu88CbkG1 helm-charts.git/config
added Qmdy135ZFG4kUALkaMhr6Cy3VhhkxyAh264kyg3725x8be helm-charts.git/description
added QmUJ43sv5NVRBmfPHBwEitpz6D46xh4E79ponctVXEeMSH helm-charts.git/hooks/applypatch-msg.sample
added QmeuAksU8iLW2YeirL69ibjGxkNUjWkKq5iEvWhSdeRRXF helm-charts.git/hooks/commit-msg.sample
added QmV1Jv4eQcHrYtf97nofmUjzaaa6hmVXVt4LsqeG3hQKx8 helm-charts.git/hooks/fsmonitor-watchman.sample
added QmWkzb9d617XFnahXuorAQPxRMGA8TeZB7Vyq2oBMmW52d helm-charts.git/hooks/post-update.sample
added QmdgKBitxhbQ3APZt3CFAnfJUMCNC5uoGLkwjgbHciKPA8 helm-charts.git/hooks/pre-applypatch.sample
added QmVpNrG3G8aMcdScqwAkiKan2ACx6bfR35Dn9XJ2mw3LCC helm-charts.git/hooks/pre-commit.sample
added QmPep4RB3J5ERq3wrwEKFLznjnJeeFPqHZUjqcT3mCHej6 helm-charts.git/hooks/pre-merge-commit.sample
added QmQ52euRcb4YZf8PYfajNPQAuaW8WoBgzAksUqHLLttqjk helm-charts.git/hooks/pre-push.sample
added QmaTMXXEbvRSmpDTKqXf6kH3yeb7TNbiu3jttyYCbFpobD helm-charts.git/hooks/pre-rebase.sample
added QmNgDPe6oFz5jqqqdh9YhuqReBWkuPo6gsy45nHB6mSr2j helm-charts.git/hooks/pre-receive.sample
added QmPgMWyjZR1FzFaB1bYAWKkYLTtC5b6DGFVKroQp5eT7Ee helm-charts.git/hooks/prepare-commit-msg.sample
added QmW7VnBMgFcJNVCKfSNZRL5apU8X19mp7bsL8px6zjbmGn helm-charts.git/hooks/push-to-checkout.sample
added QmdBgUSUM2gmuHYMsk8Xy8AkWU5orkGKeBdK9JjfSCM2tC helm-charts.git/hooks/update.sample
added QmcfzxUpw36y8fu2GR3s7Vgq7RBgooKtc6BgsqFnadsDLc helm-charts.git/info/exclude
added QmW2BhLpMEmyhmvVi5xfRcym54NQEH5RfsqAyaL47NKzr1 helm-charts.git/info/refs
added QmYFqkUdpTZ2TwbpRwnyo7K4zMu8Ep9wWTpKELxHS33qiQ helm-charts.git/objects/info/packs
added QmPd9zs6bXigRrxEfLgpdV7nRmGF6UDgGLBiU4jz1zyfm8 helm-charts.git/objects/pack/pack-7d12aca4cae291e85bdb043dcbc34cc5ecf55d2d.idx
added QmX7zrvm2e2cAkLiakS4r8bqWTW7u8onxLuS4BXNUrBzSz helm-charts.git/objects/pack/pack-7d12aca4cae291e85bdb043dcbc34cc5ecf55d2d.pack
added QmZ9Es1CLRGWzasb4w3QRfvUi7NowtA78QKVuZahrMF1ix helm-charts.git/packed-refs
added QmUNLLsPACCz1vLxQVkXqqLX5R1X345qqfHbsf67hvA3Nn helm-charts.git/branches
added QmUDWwEzg33DPr6NNxeBDKgHKaTcDfbVfJrog6HpzLXTvg helm-charts.git/hooks
added QmXpvGWuzK8rPGrC7sDGsy7USx6v5mWgm1zfD2FGek5mwT helm-charts.git/info
added QmPmEe7i3mFqU1DfkENkkH1to3QrWJD5UGSNJ7tmQ3cCUy helm-charts.git/objects/info
added QmaodTHHrn5BZY8zaq4Lpj5Af4CmnQKbYract1aadwP8Aq helm-charts.git/objects/pack
added QmfBTRmFNY3t5UP4s2bRFtmNAi4jiffcHBiokxxLeVEjzE helm-charts.git/objects
added QmUNLLsPACCz1vLxQVkXqqLX5R1X345qqfHbsf67hvA3Nn helm-charts.git/refs/heads
added QmUNLLsPACCz1vLxQVkXqqLX5R1X345qqfHbsf67hvA3Nn helm-charts.git/refs/tags
added QmWYtSEta2Fzgy4u4ttdwwiKMUikwZrFHxa5quWXMVyBhy helm-charts.git/refs
added QmVeBgcRdV5AapyRa8wcfLsk8y4xWxAL93mTmyCdrEynR5 helm-charts.git
491.68 KiB / 491.68 KiB [========================================================================================================================================================]
We can now clone our repository using our local node:
# Using our local gateway
git clone http://QmVeBgcRdV5AapyRa8wcfLsk8y4xWxAL93mTmyCdrEynR5.ipfs.localhost:8080
# Using a public gateway
git clone https://ipfs.io/ipfs/QmVeBgcRdV5AapyRa8wcfLsk8y4xWxAL93mTmyCdrEynR5/
Conclusion
I discovered IPFS while reading an article about the censorship of Wikipedia in Turkey. I don’t have a real use case other than making my articles accessible on the day I decide to close my site. I’ll let you form your own opinion and find your own usefulness.
In the meantime, I plan to archive some projects on the network and try to always keep at least one active node.