ArgoCD from A to Y

GitOps
What is GitOps?
GitOps is a methodology where Git is at the center of delivery automation processes. It serves as the “source of truth” and is coupled with programs to continuously compare the current infrastructure with that described in the Git repository.
It should not be confused with CI/CD, which involves testing the application code and delivering it. Indeed, GitOps follows the same process but incorporates other aspects of the application architecture:
- Infrastructure as code.
- Policy as code.
- Configuration as code.
- And many other X-as-Code elements.
Infrastructure Management
Example:
I want to simplify the management of my AWS infrastructure. It is possible for me to configure accounts so that the ten members of my team can modify and create EC2 instances and security-groups.
This process is a simple and user-friendly methodology, but there are still some areas of uncertainty:
- How to know who modified this EC2 instance and why?
- How to replicate exactly the same infrastructure to create dev / staging environments?
- How to ensure that the infrastructure configuration is up to date?
- For testing or debugging purposes, how to revert to a previous version of the configuration? To address these issues, it is common to use infrastructure management and/or configuration management software such as Ansible or Terraform and to limit manual changes.
However, these tools do not cover everything. Once the configuration is written, someone is needed to apply it every time it is updated. This raises new questions:
- Who should run the scripts? When? How?
- How to keep track of deployments?
- How to ensure that the launched configuration is the latest one?
- How to test this configuration before deploying it?
Most of these questions are easily answered by combining these tools with CI/CD tools (Jenkins, Gitlab CI, Github Actions, etc.). This leads to bridging the gap between the development world and the IT administration.
And that’s exactly what GitOps is: a methodology that allows using Git to manage infrastructure by using development tools to administer it.
Pull vs Push
In the GitOps universe, there are two distinct modes of operation: Push and Pull. These modes designate the actor who will be responsible for synchronizing the infrastructure with the code (what we will call the reconciliation loop).
For example, in Push mode: Jenkins can deploy the infrastructure by calling Terraform as a system administrator would have done.
In Pull mode: it is the infrastructure itself that will fetch its configuration from the Git repository. A somewhat trivial example would be a container that will download its configuration from a Git repository itself (yes, it’s not common and not very efficient, but it fits our definition well).
These two modes have advantages and disadvantages that we will detail below.
Push method
Push mode is the easiest to set up and often interfaces with tools already present in the technical stack (Terraform, Puppet, Saltstack, Ansible, etc.).
However, it requires that the identifiers/secrets necessary to administer our technical environment be usable by the CI/CD runner or somewhere in the deployment pipeline (which can be a vulnerability point).
As a result, the actor launching the deployment program becomes sensitive, and it is important to secure the supply chain to prevent this machine from revealing access.
Pull method
In Pull mode, the actor deploying the infrastructure is present within it. Given its nature, they already have the necessary access to perform their duty: comparing Git with the technical environment and ensuring that both are in sync.
The advantage is that Git is completely free of any sensitive data. The main drawback of this system is that it can be complex to set up and not all environments may be compatible.
The reconciliation loop
An important concept in GitOps is the reconciliation loop. This is the process that allows comparing the current state of the infrastructure with that described in the Git repository.
It consists of three steps:

- Observe :
- Retrieve the content of the Git repository.
- Retrieve the state of the infrastructure.
- Diff :
- Compare the repository with the infrastructure.
- Act :
- Reconcile the architecture with the content of Git.
Git in “GitOps”
With this methodology, we can always take advantage of Git to use it as intended: a collaborative tool. The use of Merge-Requests is a real asset to allow actors to propose modifications in the main branch (the one synchronized with the infra), enabling the “experts” to approve or reject these modifications.
By treating configuration or architecture as code, we gain in reliability and benefit from the same advantages as developers: history, organization, collaboration.
GitOps in Kubernetes
Kubernetes is a great example of what can be done with GitOps from its most basic usage: creating and deploying YAML/JSON manifests containing the instructions that Kubernetes must apply for the creation of an application.
It is thus possible to apply the two modes of operation of GitOps:
- Push - Perform a
kubectl applydirectly in a Gitlab Pipeline. - Pull - A pod regularly fetching (via a
git pull) the content from a repository and having sufficient permissions to apply the manifests if a commit updates them.
Today, we are going to test one of the two major tools for GitOps: ArgoCD
When to reconcile the infrastructure?
This issue is the same as during the “deployment” part of CI-CD. When should we reconcile our Git repository with our machines?
Like any good SRE, I will answer you “it depends”.
Depending on the cost of a deployment, it may be appropriate to limit interactions to deploy only major changes (or even a series of minor modifications).
Note
By “cost”, I obviously mean money, but also potential “downtime” caused by the reconciliation loop.
Deploying with each commit can be interesting but very costly, while deploying every night (when few users are present) may require organization to test the deployment.
The three ways to do it are:
- Reconcile with each change in the main branch.
- Reconcile every X time.
- Reconcile manually.
Tip
It is advisable to make commits in a separate branch before merging it into the main branch to trigger deployment. This way, a commit can contain many modifications.
ArgoCD
ArgoCD Operation
ArgoCD is one of the programs that allows comparing the content of a cluster with that of a Git repository. It has the advantage of being easy to use and extremely flexible for teams.
What is ArgoCD?
ArgoCD is a program that allows comparing a truth source on Git with a Kubernetes cluster. It has many features such as:
- Automatic Drift detection (if a user has manually modified the code directly on the cluster).
- A WebUI interface for cluster administration.
- The ability to manage multiple clusters.
- A CLI to manage ArgoCD.
- Contains a native Prometheus exporter.
- Allows pre/post reconciliation actions.
Installation
ArgoCD is a program that can be installed on a Kubernetes cluster in several ways:
- A complete bundle with WebUI and CLI,
- A minimal bundle with only the CRDs.
In this article, I will install a complete ArgoCD (with WebUI and CLI) on a Kubernetes cluster.
kubectl create namespace argocd
kubectl apply -n argocd -f https://raw.githubusercontent.com/argoproj/argo-cd/stable/manifests/install.yaml
To access our freshly installed ArgoCD (whether through WebUI or CLI), we need a password. This password is generated automatically and stored in a Kubernetes secret.
Get the default password:
kubectl -n argocd get secret argocd-initial-admin-secret -o jsonpath="{.data.password}" | base64 -d
You can now create a proxy to access the WebUI (or use a LoadBalancer / Ingress service).
Info
If you want to expose the ArgoCD service in an Ingress/HTTPRoute, you will certainly need to disable TLS:
kubectl patch configmap argocd-cmd-params-cm -n argocd --type merge --patch '{"data": {"server.insecure": "true"}}'
Managing ArgoCD via CLI
Installing the CLI
Apart from Pacman, the command-line utility is not available in the repositories of most distributions. Therefore, it is necessary to download it manually.
curl -sSL -o argocd-linux-amd64 https://github.com/argoproj/argo-cd/releases/latest/download/argocd-linux-amd64
sudo install -m 555 argocd-linux-amd64 /usr/local/bin/argocd
rm argocd-linux-amd64
Other installation methods are available in the official documentation
Connecting to ArgoCD
There are several ways to connect to ArgoCD, the simplest being to connect with credentials:
- Use a password:
argocd login argocd.une-pause-cafe.fr
- Use the kubeconfig:
argocd login --core
- Use a token:
argocd login argocd.une-pause-cafe.fr --sso
Deploying your first application with ArgoCD
Let’s not rush into things, so let’s start with what ArgoCD does best: deploying an application, nothing more, nothing less.
For this, there are several ways:
- Use the WebUI
- Use the ArgoCD CLI
- Use the
ApplicationCRD
In this article, I will strongly favor the use of CRDs to deploy applications (or even projects) because it is the only component that will always be present with ArgoCD. The CLI and the WebUI are optional and can be disabled, but not the CRDs.
If you’re unsure what to deploy, I suggest several test applications on my Git repository: Kubernetes Coffee Image
This repository contains multiple deployable applications in various ways: Helm, Kustomize, or even raw manifests.
Let’s create our first application with the simplest image: time-coffee which simply displays a coffee image along with the pod’s hostname.
apiVersion: argoproj.io/v1alpha1
kind: Application
metadata:
name: simple-app
namespace: argocd
spec:
destination:
namespace: simple-app
server: https://kubernetes.default.svc
project: default
source:
path: simple/chart
repoURL: https://github.com/QJoly/kubernetes-coffee-image
targetRevision: main
syncPolicy:
syncOptions:
- CreateNamespace=true
What does this manifest do? It deploys an application named simple-app from the files available in the Git repository at the path simple/chart.
ArgoCD does not need us to specify the files to select (the folder is enough) or even the format of these files (kustomize, helm, etc.). It will automatically detect the nature of these files and apply the changes accordingly.
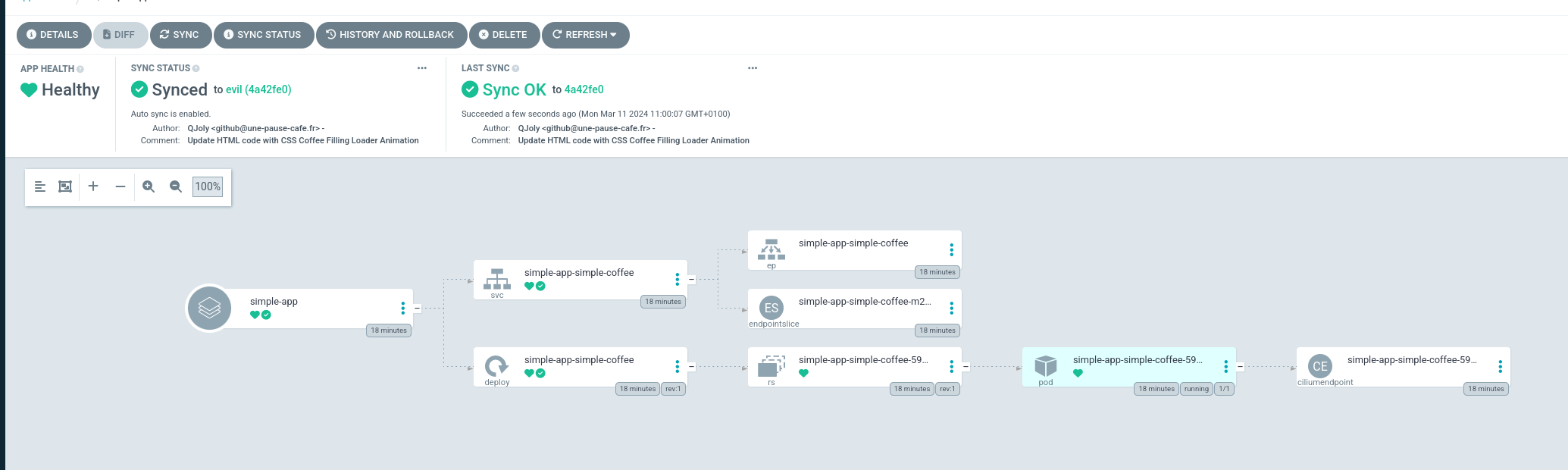
When you return to the ArgoCD web interface (or use the CLI), you should see your application in the OutOfSync status. This means that the application has not been deployed to the cluster yet.
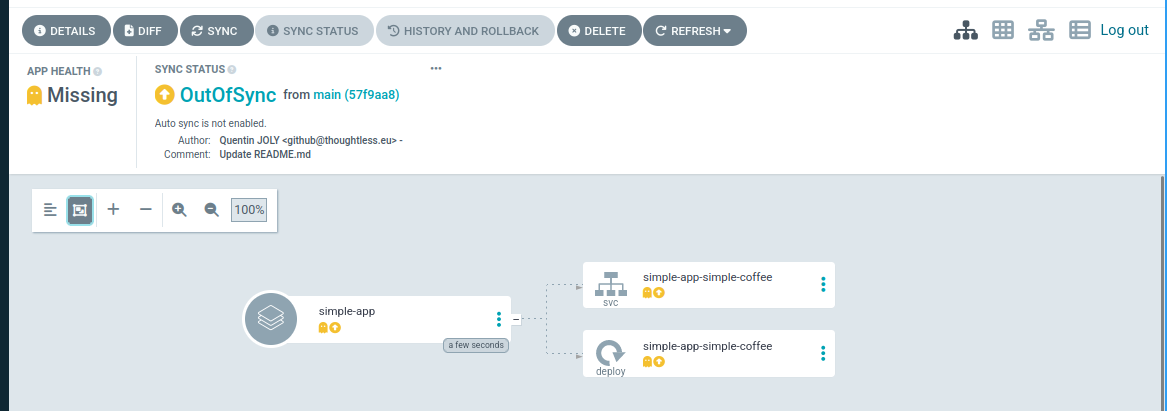
$ argocd app list
NAME CLUSTER NAMESPACE PROJECT STATUS HEALTH SYNCPOLICY CONDITIONS REPO PATH TARGET
argocd/simple-app https://kubernetes.default.svc simple-app default OutOfSync Missing <none> <none> https://github.com/QJoly/kubernetes-coffee-image simple/chart main
To force reconciliation (and thus deploy the application), simply click on the “Sync” button in the WebUI interface or run the command argocd app sync simple-app.
After a few seconds (the time it takes for Kubernetes to apply the changes), the application should be deployed and its status should be Synced.
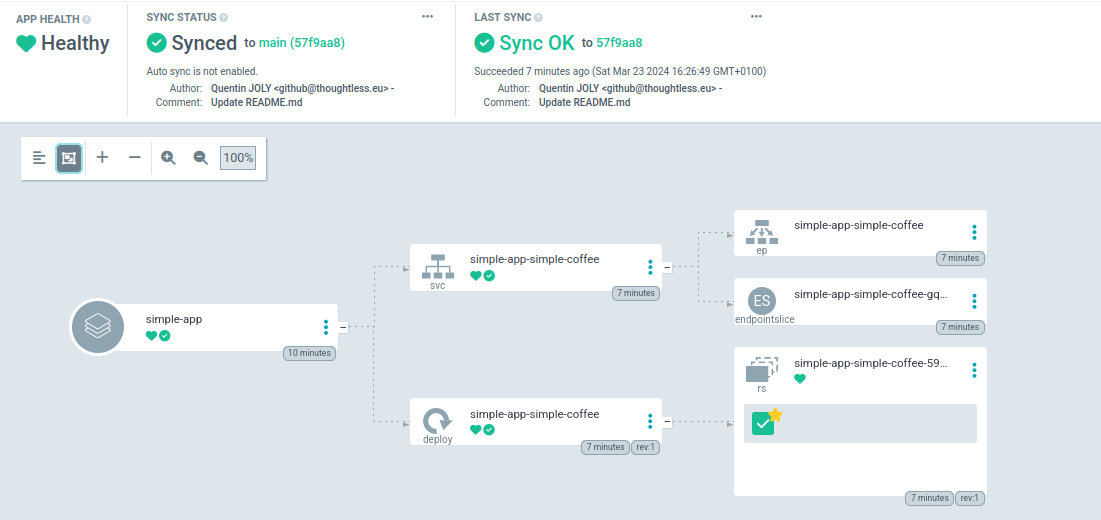
You now have the foundation to deploy an application with ArgoCD.
Refreshing the repository every X time
By default, ArgoCD will refresh the content of the repository every 3 minutes. It is possible to change this behavior to reduce the load on the cluster if ArgoCD is used for many projects (or if the cluster is heavily utilized).
Info
Note that refreshing the repository does not imply the application reconciliation. You will need to enable the auto-sync option for that.
To do this, you need to set the environment variable ARGOCD_RECOCILIATION_TIMEOUT in the argocd-repo-server pod (which itself uses the timeout.reconciliation variable in the argocd-cm configmap).
$ kubectl -n argocd describe pods argocd-repo-server-58c78bd74f-jt28g | grep "RECONCILIATION"
ARGOCD_RECONCILIATION_TIMEOUT: <set to the key 'timeout.reconciliation' of config map 'argocd-cm'> Optional: true
Update the configmap argocd-cm to change the value of timeout.reconciliation:
kubectl -n argocd patch configmap argocd-cm -p '{"data": {"timeout.reconciliation": "3h"}}'
kubectl -n argocd rollout restart deployment argocd-repo-server
Thus, the Git refresh will be done every 3 hours. If automatic reconciliation is enabled and there is no sync window, the cluster will be reconciled every 3 hours.
Refreshing the repository on each commit
In contrast to regular reconciliation, it is possible to automatically refresh the Git on each code modification. For this, a webhook will be set up on Github / Gitlab / Bitbucket / Gitea etc.
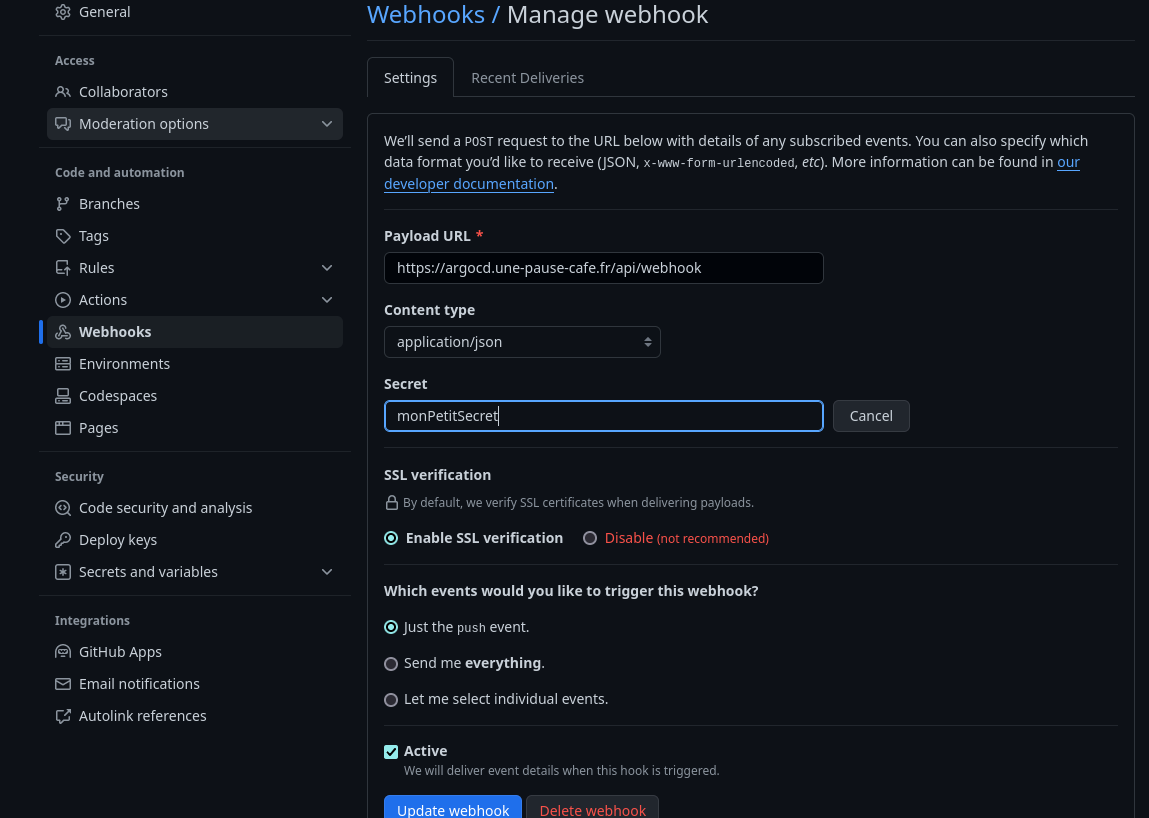
An optional step (but one that I find essential) is to create a secret so that ArgoCD only accepts webhooks when they have this secret.
Info
Not setting up this secret is equivalent to allowing anyone to trigger a reconciliation on the cluster and thus DoS the ArgoCD pod.
I choose the value monPetitSecret that I will convert to Base64 (mandatory for Kubernetes secrets) :
$ echo -n "monPetitSecret123" | base64
bW9uUGV0aXRTZWNyZXQ=
Depending on the Git server used, the key used by ArgoCD will be different:
- Github:
webhook.github.secret - Gitlab:
webhook.gitlab.secret - Gog/Gitea:
webhook.gog.secret
I am using Github (so the key webhook.github.secret) :
kubectl -n argocd patch cm argocd-cm -p '{"data": {"webhook.github.secret": "bW9uUGV0aXRTZWNyZXQ="}}'
kubectl rollout -n argocd restart deployment argocd-server
Next, I go to my Github repository, in Settings > Webhooks and create a new webhook. I choose the type application/json and enter the URL of my Kubernetes cluster (or LoadBalancer / Ingress service) followed by /api/webhook (for example https://argocd.mycluster.com/api/webhook).
Warning
If the ArgoCD console displays the error Webhook processing failed: HMAC verification failed when receiving a webhook, there can be multiple reasons:
- The secret is incorrect.
- The secret contains special characters that are not interpreted correctly.
- The request is not in JSON.
After using a random secret, I had to change it to a simpler secret containing only alphanumeric characters: a-zA-Z0-9.
Synchronization Strategy
It is possible to define many parameters for application synchronization.
Auto-Pruning
This feature is very interesting to avoid keeping unnecessary resources in the cluster. During a reconciliation, ArgoCD will delete resources that are no longer present in the Git repository.
To activate it from the command line:
argocd app set argocd/simple-app --auto-prune
Or from the application manifest (to be placed in the spec of the application):
syncPolicy:
automated:
prune: true
Self-Heal
Self-heal is a feature that allows the cluster to automatically reconcile if a resource is manually modified. For example, if a user modifies a secret, ArgoCD will notice this difference between the cluster and the source of truth before removing this delta.
To activate it from the command line:
argocd app set argocd/simple-app --self-heal
Or from the application manifest (to be placed in the spec of the application):
syncPolicy:
automated:
selfHeal: true
Health Checks
When ArgoCD reconciles the cluster with the Git repository, it will display a health status for each application (Healthy, Progressing, Degraded, Missing). At first, I didn’t pay much attention to it, but it can be interesting to understand what these statuses mean and how ArgoCD determines them.
For objects like secrets or configmaps, the presence of the object in the cluster is sufficient for the entity to be Healthy. For a LoadBalancer type service, ArgoCD will verify that the service is properly exposed on the expected IP by checking that the value of status.loadBalancer.ingress is not empty.
It is possible to create custom Healthchecks for objects not included in the list of objects supported by ArgoCD by creating a small Lua code in the argocd-cm configmap:
An example (available in the ArgoCD documentation) for certificates managed by cert-manager:
resource.customizations: |
cert-manager.io/Certificate:
health.lua: |
hs = {}
if obj.status ~= nil then
if obj.status.conditions ~= nil then
for i, condition in ipairs(obj.status.conditions) do
if condition.type == "Ready" and condition.status == "False" then
hs.status = "Degraded"
hs.message = condition.message
return hs
end
if condition.type == "Ready" and condition.status == "True" then
hs.status = "Healthy"
hs.message = condition.message
return hs
end
end
end
end
hs.status = "Progressing"
hs.message = "Waiting for certificate"
return hs
Ignore automatically created resources
As soon as I deploy a Helm Chart, Cilium will automatically create a CiliumIdentity object in the cluster (used to create firewall rules directly with the chart name). This resource is not present in my Git repository and ArgoCD does not appreciate this difference.
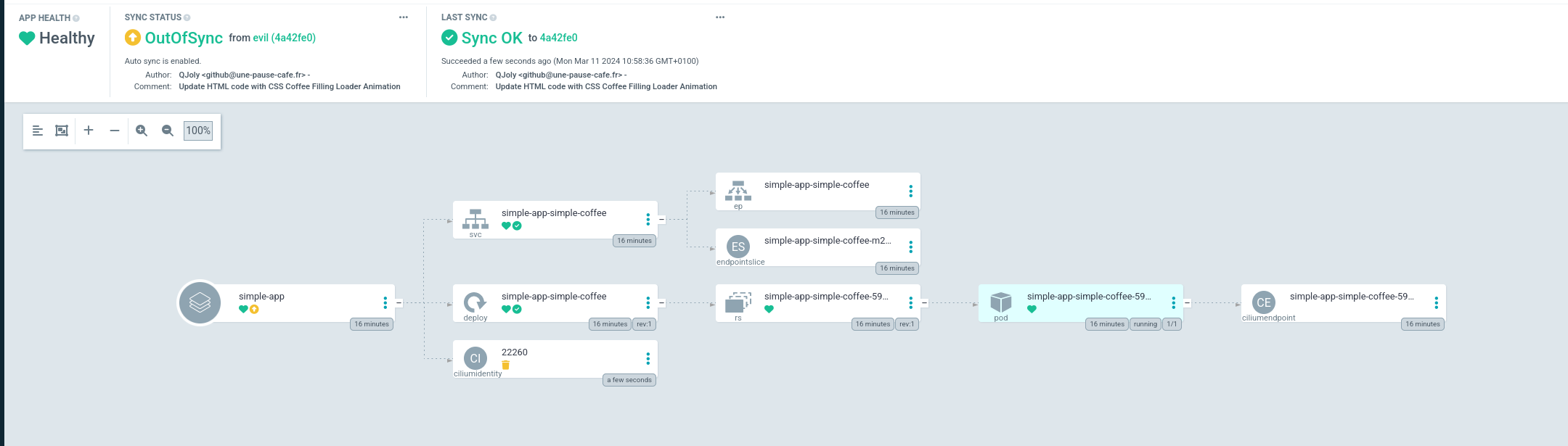
That’s why I can ask it to systematically ignore resources of a certain type. To do this, I will modify the argocd-cm configmap to add an exclusion.
resource.exclusions: |
- apiGroups:
- cilium.io
kinds:
- CiliumIdentity
clusters:
- "*"
After restarting ArgoCD (kubectl -n argocd rollout restart deployment argocd-repo-server), it should no longer display this difference.
I would have liked this option to be configurable per application, but it is not currently possible.
Override variables
A mandatory feature for most applications is overriding variables directly from ArgoCD. This allows you to change a value without modifying the Git repository and without being constrained by the default configuration.
There are many ways to override variables in ArgoCD. Here is an example for Kustomize:
apiVersion: argoproj.io/v1alpha1
kind: Application
metadata:
name: versioned-coffee
namespace: argocd
spec:
project: default
source:
repoURL: 'https://github.com/QJoly/kubernetes-coffee-image'
path: evil-tea/kustomize
targetRevision: evil
kustomize:
patches:
- patch: |-
- op: replace
path: /metadata/name
value: mon-mechant-deploy
target:
kind: Deployment
name: evil-tea-deployment
destination:
server: 'https://kubernetes.default.svc'
namespace: evil-ns
And with Helm:
apiVersion: argoproj.io/v1alpha1
kind: Application
metadata:
name: versioned-coffee
namespace: argocd
spec:
destination:
namespace: versioned-coffee
server: https://kubernetes.default.svc
project: default
source:
helm:
parameters:
- name: service.type
value: NodePort
path: multiversions/chart
repoURL: https://github.com/QJoly/kubernetes-coffee-image
targetRevision: main
syncPolicy:
syncOptions:
- CreateNamespace=true
Deploying an application on multiple clusters
Currently, we are only using a single cluster: the one where ArgoCD is installed. However, it is possible to deploy an application on multiple clusters without having to install a second ArgoCD.
For this purpose, it can be easily configured using the command-line utility (another way is to generate multiple secrets forming the equivalent of a kubeconfig).
I will create a second cluster and configure it in my local file ~/.kube/config:
$ kubectl config get-contexts
CURRENT NAME CLUSTER AUTHINFO NAMESPACE
* admin@homelab-talos-dev homelab-talos-dev admin@homelab-talos-dev argocd
admin@temporary-cluster temporary-cluster admin@temporary-cluster default
My cluster will therefore be temporary-cluster and I will configure it in ArgoCD using the command argocd cluster add [context name]. This will create a service account on the cluster so it can manage it remotely.
$ argocd cluster add admin@temporary-cluster
WARNING: This will create a service account `argocd-manager` on the cluster referenced by context `admin@temporary-cluster` with full cluster level privileges. Do you want to continue [y/N]? y
INFO[0017] ServiceAccount "argocd-manager" created in namespace "kube-system"
INFO[0017] ClusterRole "argocd-manager-role" created
INFO[0017] ClusterRoleBinding "argocd-manager-role-binding" created
INFO[0022] Created bearer token secret for ServiceAccount "argocd-manager"
Cluster 'https://192.168.1.97:6443' added
Returning to the WebUI interface, I can see that my second cluster is indeed present.
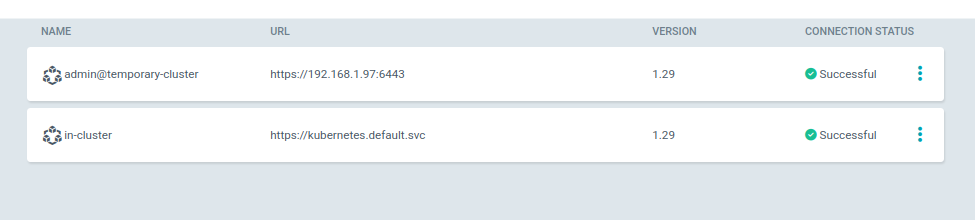
$ argocd cluster list
SERVER NAME VERSION STATUS MESSAGE PROJECT
https://192.168.1.97:6443 admin@temporary-cluster 1.29 Successful
https://kubernetes.default.svc in-cluster
When I add an application in ArgoCD, I can now select the cluster on which I want to deploy it.
apiVersion: argoproj.io/v1alpha1
kind: Application
metadata:
name: versioned-coffee
namespace: argocd
spec:
destination:
namespace: versioned-coffee
server: https://192.168.1.97:6443
project: default
source:
helm:
parameters:
- name: service.type
value: NodePort
path: multiversions/chart
repoURL: https://github.com/QJoly/kubernetes-coffee-image
targetRevision: main
syncPolicy:
syncOptions:
- CreateNamespace=true
Application Sets
Application Sets are a feature of ArgoCD that allows creating application templates. The idea is to have an application template that will be duplicated for each element in a list.
Here are some examples of use:
- Deploying the same application in multiple namespaces.
- Deploying the same application on multiple clusters.
- Deploying the same application with different values.
- Deploying multiple versions of an application.
To create an Application Set, simply create a YAML file containing the list of applications to deploy.
For example, if I want to deploy all versions of my versioned-coffee application in 3 different namespaces:
apiVersion: argoproj.io/v1alpha1
kind: ApplicationSet
metadata:
name: versioned-coffee
namespace: argocd
spec:
generators:
- list:
elements:
- namespace: alpha
tag: v1.1
- namespace: dev
tag: v1.2
- namespace: staging
tag: v1.3
- namespace: prod
tag: v1.4
template:
metadata:
name: versioned-coffee-{{namespace}}
spec:
project: default
source:
helm:
parameters:
- name: image.tag
value: {{tag}}
path: multiversions/chart
repoURL: https://github.com/QJoly/kubernetes-coffee-image
targetRevision: main
destination:
namespace: {{namespace}}
server: 'https://kubernetes.default.svc'
syncPolicy:
automated:
selfHeal: true
syncOptions:
- CreateNamespace=true
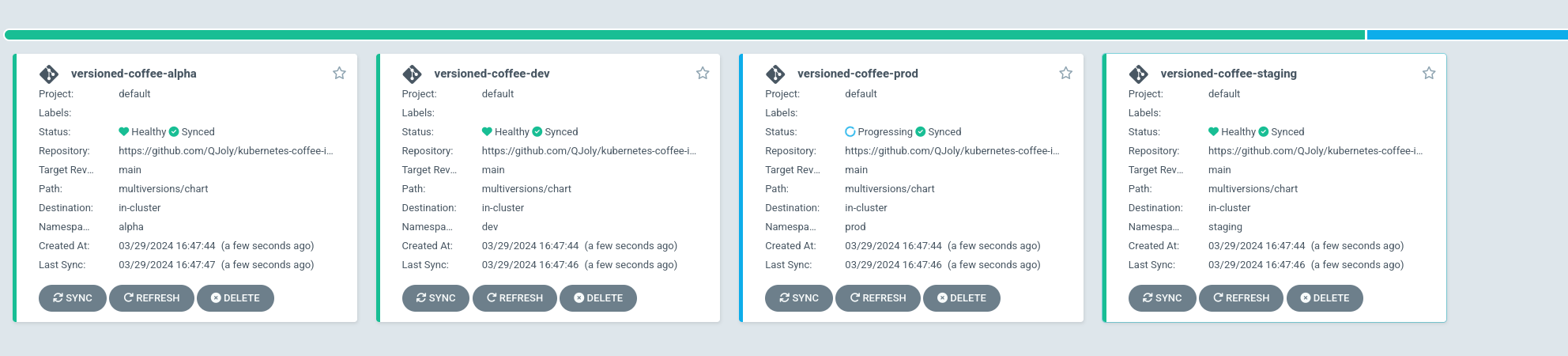
After a few seconds: I have 4 versioned-coffee applications deployed in 4 different namespaces.
But using a static list is not the only way to create an ApplicationSet. It is possible to use external sources like ‘Generators’ to create dynamic applications:
- The list of Kubernetes clusters connected to ArgoCD.
- A folder in a Git repository (
./apps/charts/*). - All Git repositories of a user/organization.
- Deploy pull-requests on a Git repository.
- An external API (for example, a ticketing service).
It is also possible to combine generators together to create more complex applications.
To deploy an application on multiple clusters, I can use the cluster generator. I can then deploy an application on all clusters, or only on those I want to target.
To select all clusters, simply use an empty list:
generators:
- clusters: {}
I can also select clusters based on the name:
generators:
- clusters:
names:
- admin@temporary-cluster
Or a label on the secret (secret created by argocd cluster add):
# With a match on the staging label
generators:
- clusters:
selector:
matchLabels:
staging: true
# Or with matchExpressions
generators:
- clusters:
matchExpressions:
- key: environment
operator: In
values:
- staging
- dev
During this demonstration, I have two clusters in ArgoCD: production-cluster-v1 and staging-cluster-v1.
$ kubectl config get-contexts
CURRENT NAME CLUSTER AUTHINFO NAMESPACE
* admin@core-cluster core-cluster admin@core-cluster argocd
admin@production-cluster-v1 production-cluster-v1 admin@production-cluster-v1 default
admin@staging-cluster-v1 staging-cluster-v1 admin@staging-cluster-v1 default
$ argocd cluster list
SERVER NAME VERSION STATUS MESSAGE PROJECT
https://192.168.1.98:6443 staging-cluster-v1 1.29 Successful
https://192.168.1.97:6443 production-cluster-v1 1.29 Successful
https://kubernetes.default.svc in-cluster
I will create the ApplicationSet that will deploy the simple-coffee application on clusters whose secret contains the label app: coffee.
apiVersion: argoproj.io/v1alpha1
kind: ApplicationSet
metadata:
name: simple-coffee
namespace: argocd
spec:
generators:
- clusters:
selector:
matchLabels:
app: coffee
template:
metadata:
name: 'simple-coffee-{{name}}'
spec:
project: default
source:
path: multiversions/chart
repoURL: https://github.com/QJoly/kubernetes-coffee-image
targetRevision: main
destination:
namespace: simple-coffee
server: '{{server}}'
syncPolicy:
automated:
selfHeal: true
syncOptions:
- CreateNamespace=true
If we look at the deployed applications, we can see that the application is not deployed on any cluster (as none of them have the app: coffee label).
argocd app list
NAME CLUSTER NAMESPACE PROJECT STATUS HEALTH SYNCPOLICY CONDITIONS REPO PATH TARGET
We will add this label to the secret of the staging-cluster-v1 cluster.
kubectl label -n argocd secrets cluster-staging-v1 "app=coffee"
Instantly, the simple-coffee-staging-cluster-v1 application is added to ArgoCD and deployed on the staging-cluster-v1 cluster (and only on this one).
$ argocd app list
NAME CLUSTER NAMESPACE PROJECT STATUS HEALTH SYNCPOLICY CONDITIONS REPO PATH TARGET
argocd/simple-coffee-staging-cluster-v1 https://192.168.1.98:6443 simple-coffee default Synced Healthy Auto <none> https://github.com/QJoly/kubernetes-coffee-image multiversions/chart main
Warning
In the manifest above, I used the variable {{name}} to retrieve the cluster name. But if it contains special characters, you will need to update this name to comply with RFC 1123.
By default, when adding a cluster to ArgoCD using the argocd cluster add command, the cluster name is the context name.
For example, if my cluster name is admin@production-cluster-v1, I can rename it using the following process:
secretName="cluster-production-v1-sc" # Nom du secret utilisé par ArgoCD pour stocker les informations du cluster
clusterName=$(kubectl get secret ${secretName} -n argocd -o jsonpath="{.data.name}" | base64 -d) # admin@production-cluster-v1
clusterName=$(echo ${clusterName} | sed 's/[^a-zA-Z0-9-]/-/g') # admin-production-cluster-v1
kubectl patch -n argocd secret ${secretName} -p '{"data":{"name": "'$(echo -n ${clusterName} | base64)'"}}'
The new name of the cluster will then be admin-production-cluster-v1.
If I ever want to deploy the application on the production cluster, all I have to do is add the label app: coffee:
kubectl label -n argocd secrets cluster-production-v1 "app=coffee"
$ argocd app list
NAME CLUSTER NAMESPACE PROJECT STATUS HEALTH SYNCPOLICY CONDITIONS REPO PATH TARGET
argocd/simple-coffee-admin-production-cluster-v1 https://192.168.1.97:6443 simple-coffee default Synced Healthy Auto <none> https://github.com/QJoly/kubernetes-coffee-image multiversions/chart main
argocd/simple-coffee-staging-cluster-v1 https://192.168.1.98:6443 simple-coffee default Synced Healthy Auto <none> https://github.com/QJoly/kubernetes-coffee-image multiversions/chart main
And if I want to remove the application from the staging cluster, I remove the label:
kubectl label -n argocd secrets cluster-staging-v1-sc app-
ArgoCD Image Updater
ArgoCD Image Updater is a tool that automatically updates the images of applications deployed by ArgoCD.
Why? Because every time a new image is available, you would need to modify the manifest to update it. This is a tedious task that can be automated by CI/CD or by ArgoCD Image Updater.
The goal is to delegate this task to ArgoCD, which will regularly check if a new image is available and update it if that’s the case.
This update can be done in several ways:
- By overriding the manifest variables (Helm, Kustomize) in the ArgoCD application.
- By creating a commit on the Git repository for ArgoCD to take into account (which requires write access to the Git repository).
It is also important to consider the following questions: “Which image will we use?” and “How do we know if a new image is available?”.
ArgoCD Image Updater can be configured in four different ways:
semver: For images using the semantic versioning format (1.2.3) in the tag.latest: Always use the latest created image (regardless of its tag).digest: Update the image digest (while keeping the same tag).name: Update the image tag using the last tag in alphabetical order (can also be combined with a regex to ignore certain tags).
Installation
kubectl apply -n argocd -f https://raw.githubusercontent.com/argoproj-labs/argocd-image-updater/stable/manifests/install.yaml
Configuration
For this demonstration, I will base myself on the semver method.
My repository contains several images with semantic versioning tags: v1, v2, v3, and v4. These are PHP applications displaying one coffee for v1, two for v2, three for v3, etc.
Let’s create an ArgoCD application using the v1 image (used by default in the chart).
apiVersion: argoproj.io/v1alpha1
kind: Application
metadata:
name: versioned-coffee
namespace: argocd
spec:
destination:
namespace: versioned-coffee
server: https://kubernetes.default.svc
project: default
source:
helm:
parameters:
- name: service.type
value: NodePort
path: multiversions/chart
repoURL: https://github.com/QJoly/kubernetes-coffee-image
targetRevision: main
syncPolicy:
syncOptions:
- CreateNamespace=true
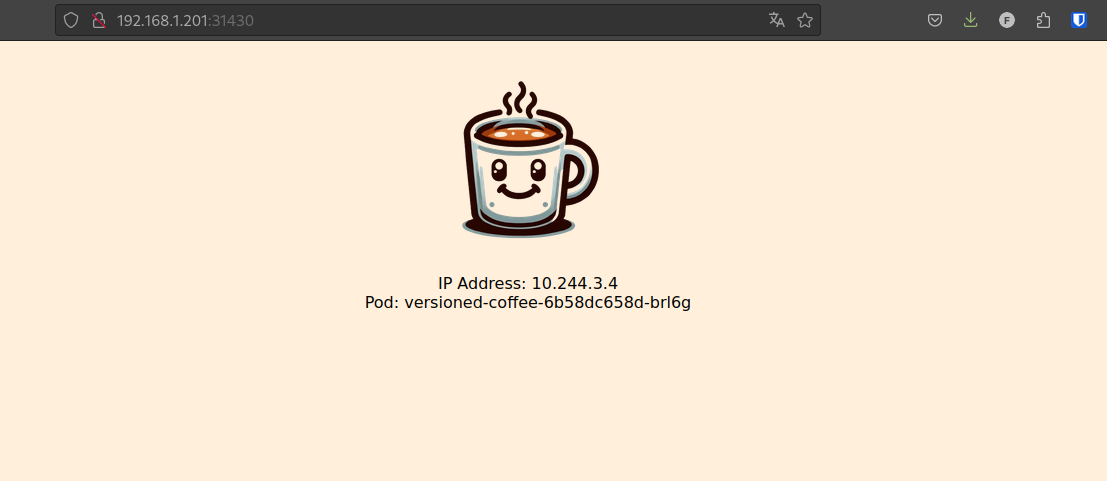
By default, my values.yaml file uses the image qjoly/kubernetes-coffee-image:v1.
By opening the NodePort of our application, we can see that the v1 image is deployed (there is indeed one coffee).
As a cluster administrator, if I learn that a new image is available, I can update my ArgoCD application to use a new tag corresponding to the new image.
argocd app set versioned-coffee --parameter image.tag=v2
This will have the effect of overriding the image.tag variable in the values.yaml file of my Helm application.
project: default
source:
repoURL: 'https://github.com/QJoly/kubernetes-coffee-image'
path: multiversions/chart
targetRevision: main
helm:
parameters:
- name: service.type
value: NodePort
- name: image.tag
value: v2
destination:
server: 'https://kubernetes.default.svc'
namespace: versioned-coffee
syncPolicy:
syncOptions:
- CreateNamespace=true
Let’s say we are on a development platform that needs to be up to date, it quickly becomes tedious to manually update the tag every time a new version is available.
This is where ArgoCD Image Updater comes in. It can automate the process of updating image tags based on the chosen method.
We add an annotation to our ArgoCD application to indicate that it should monitor the images in our repository.
kubectl -n argocd patch application versioned-coffee --type merge --patch '{"metadata":{"annotations":{"argocd-image-updater.argoproj.io/image-list":"qjoly/kubernetes-coffee-image:vx"}}}'
By adding the annotation argocd-image-updater.argoproj.io/image-list with the value qjoly/kubernetes-coffee-image:vx, I am asking ArgoCD Image Updater to monitor the images in my repository.
By default, it will automatically update the image.tag and image.name keys in the values.yaml file of my Helm application.
Info
If your values.yaml has a different syntax (for example, the tag is under the key app1.image.tag, it is still possible to update this key).
argocd-image-updater.argoproj.io/image-list: coffee-image=qjoly/kubernetes-coffee-image:vx
argocd-image-updater.argoproj.io/coffee-image.helm.image-name: app1.image.name
argocd-image-updater.argoproj.io/coffee-image.helm.image-tag: app1.image.tag
On the web interface, ArgoCD indicates that the repository is Out of sync. Clicking the Sync button allows to update the application’s tag:

You can also couple this with automatic synchronization if needed.
Application of Applications
ArgoCD allows deploying applications that will deploy others. It’s a bit like the principle of “composition” in programming.
Why do this? To deploy applications that have dependencies between them. For example, if I want to deploy an application that needs a database, I can deploy the database with ArgoCD and then deploy the application.
apiVersion: argoproj.io/v1alpha1
kind: Application
metadata:
name: applications
namespace: argocd
spec:
destination:
server: https://kubernetes.default.svc
project: default
source:
path: argocd-applications
repoURL: https://github.com/QJoly/kubernetes-coffee-image
targetRevision: HEAD
Create users
ArgoCD allows creating users to log in to the web interface. It is possible to log in with credentials, with a token, or with SSO.
To create a user, I must add them directly to the configmap argocd-cm:
kubectl -n argocd patch configmap argocd-cm --patch='{"data":{"accounts.michele": "apiKey,login"}}'
This command allows creating a user michele who can generate API tokens on her behalf and log in with a password to the ArgoCD web interface.
To assign a password to this user, I must use the command argocd account update-password --account michele.
Now, Michèle cannot do anything on my ArgoCD, she cannot create or view applications, let’s fix that.
The ArgoCD RBAC system works with a principle of policies that I will assign to a user or a role.
A policy can authorize an action to a user or a group. These actions can be broken down in several ways:
- Rights on a specific ‘application’ (
project/application). - Rights on a specific ‘action’ (e.g.,
p, role:org-admin, logs, get, *, allow(retrieve logs from all applications)).
I will create a guest role that will be limited to read-only access on all applications in the default project.
policy.csv: |
p, role:guest, applications, get, default/*, allow
g, michele, role:guest
Now, I want her to be able to synchronize the simple-app application in the default project:
policy.csv: |
p, role:guest, applications, get, default/*, allow
p, michele, applications, sync, default/simple-app, allow
g, michele, role:guest
Create a project and manage permissions
A project is a grouping of applications to which we can assign roles and users. This allows for more fine-grained permission management and restricts access to certain applications.
Michèle works in the Time-Coffee project and needs permissions to create and manage applications in this project.
These applications will be limited to the time-coffee namespace of the cluster where argocd is installed, and she will not be able to see applications from other projects.
As an administrator, I will also limit the Git repositories that can be used in this project.
Let’s first create the Time-Coffee project:
apiVersion: argoproj.io/v1alpha1
kind: AppProject
metadata:
name: time-coffee
namespace: argocd
spec:
clusterResourceWhitelist:
- group: '*'
kind: '*'
destinations:
- name: in-cluster
namespace: '*'
server: https://kubernetes.default.svc
sourceNamespaces:
- time-coffee
sourceRepos:
- https://github.com/QJoly/kubernetes-coffee-image
- https://git.internal.coffee/app/time-coffee
- https://git.internal.coffee/leonardo/projects/time-coffee
I can now create a time-coffee-admin role for Michèle and time-coffee-developer (only in the time-coffee project).
p, role:time-coffee-admin, *, *, time-coffee/*, allow
g, michele, role:time-coffee-admin
p, role:time-coffee-developper, applications, sync, time-coffee/*, allow
p, role:time-coffee-developper, applications, get, time-coffee/*, allow
I will add the developer “Leonardo” who also works on the Time-Coffee project. He only needs to synchronize the applications after pushing to the Git repository.
g, leonardo, role:time-coffee-developper
The Time-Coffee project is now ready to be used by Michèle and Leonardo without them being able to access resources from other namespaces.
… Or maybe not?
Leonardo’s password is compromised and a nasty pirate manages to connect to ArgoCD using his credentials. Luckily, the pirate can only trigger a synchronization on the applications of the Time-Coffee project. However, he is able to access Leonardo’s Github account and wants to hack the entire cluster to mine cryptocurrencies.
Since I have allowed all types of resources: the pirate can modify the files in the Git repository to create a ClusterRole with administrative rights on the cluster followed by a pod deploying his malware.
In this example, the ‘pirate’ application only displays pods from other namespaces. But it could have done much worse.
The mistake lies in the fact that I allowed all types of resources for the Time-Coffee project. By default, ArgoCD will intentionally block ClusterRole and ClusterRoleBinding objects to ensure project isolation.
I then remove the whitelist for cluster resources:
apiVersion: argoproj.io/v1alpha1
kind: AppProject
metadata:
name: time-coffee
namespace: argocd
spec:
destinations:
- name: in-cluster
namespace: '*'
server: https://kubernetes.default.svc
sourceNamespaces:
- time-coffee
sourceRepos:
- https://github.com/QJoly/kubernetes-coffee-image
- https://git.internal.coffee/app/time-coffee
- https://git.internal.coffee/leonardo/projects/time-coffee
Reconcile applications at a specific time
Depending on your team’s working hours, it can be interesting to reconcile applications at a specific time. For example, reconciling applications at midnight to avoid disturbing users.
To do this, it is possible to create a reconciliation rule in ArgoCD projects.
Info
Please note that this rule applies to both automatic and manual reconciliations.
I can add the syncWindows field in the manifest of my ArgoCD project to define a reconciliation window.
syncWindows:
- kind: allow # autoriser de 6h à 12h
schedule: '0 6 * * *'
duration: 6h
timeZone: 'Europe/Paris'
applications:
- 'time-coffee-*'
- kind: deny
schedule: '* * * * *'
timeZone: 'Europe/Paris'
applications:
- 'time-coffee-*'
From 12 p.m., the new ‘Sync Windows’ field shows that it is not possible to reconcile the cluster with the source of truth during this period.

Note
It is possible to allow manual synchronizations in cases of force majeure.
Normally, you should add the manualSync: true option in the window where you want to allow it. But I didn’t succeed in my case (Bug? Config error?).
Hooks
When providing files to deploy in a cluster, ArgoCD will deploy them in a specific order. It starts with namespaces, Kubernetes resources, and finally CustomResourceDefinitions (CRD).
The order is defined directly in the code
This order can be modified using Hooks, which are divided into Phases (PreSync, Sync, PostSync, etc.) and Sync Wave (which allow defining the deployment order of applications with a number within the same phase).
Phases
The phases are as follows:
PreSync, before synchronization (e.g., Check if conditions are met for deployment).Sync, during synchronization, this is the default phase when no phase is specified.PostSync, after synchronization (e.g., Verify that the deployment was successful).SyncFail, following a synchronization error (e.g., Roll back the database schema).PostDelete, after the deletion of the ArgoCD application (e.g., Clean up external resources related to the application).
These phases are configured directly in the Yaml files using annotations argocd.argoproj.io/hook.
apiVersion: v1
kind: Pod
metadata:
name: backup-db-to-s3
annotations:
argocd.argoproj.io/hook: PreSync
argocd.argoproj.io/hook-delete-policy: HookSucceeded
spec:
containers:
- name: backup-container
image: amazon/aws-cli
command: ["/bin/sh"]
args: ["-c", "aws s3 cp /data/latest.sql s3://psql-dump-coffee/backup-db.sql"]
volumeMounts:
- name: db-volume
mountPath: /data
volumes:
- name: db-volume
persistentVolumeClaim:
claimName: db-psql-dump
Usually, hooks are used to trigger tasks that are meant to be removed once their work is done. To automatically remove them once they have finished, you can use the annotation argocd.argoproj.io/hook-delete-policy: HookSucceeded.
To allow time for the resources of a phase to be ready before moving on to the next phase, ArgoCD waits for 2 seconds between each phase.
Tip
To configure this time, it is possible to modify the environment variable ARGOCD_SYNC_WAVE_DELAY in the ArgoCD pod.
Sync Waves
Within the same phase, it is possible to define a deployment order for applications with a number within the same phase using the annotation argocd.argoproj.io/sync-wave. By default, all resources have a sync-wave of 0, and ArgoCD will start with the resources with the lowest sync-wave.
To deploy an application before another, simply set a lower sync-wave (e.g., -1).
Encrypting Manifests
While writing this article, I wanted to address the lack of encryption of yaml files as the kustomize+sops combo would with FluxCD. But during a live stream on CuistOps, Rémi directed me to KSOPS, a kustomize plugin that allows encrypting yaml files on the fly (during a kustomize build).
Of course, solutions like SealedSecrets or Vault are preferable. My need is to be able to use Helm charts that do not accept using external ConfigMaps / Secrets to the charts.
Unlike other alternatives, KSOPS does not require using a modified ArgoCD image to work. It comes in the form of a patch to apply to the deployment of the ArgoCD application to modify the binaries of the argocd-repo-server container.
KSOPS Installation
The first thing to do is to enable alpha plugins in kustomize and allow command execution in the kustomization.yaml files.
To do this, you need to patch the configmap of the ArgoCD application to add the arguments --enable-alpha-plugins and --enable-exec. ArgoCD retrieves these arguments from the ConfigMap argocd-cm.
kubectl patch configmap argocd-cm -n argocd --type merge --patch '{"data": {"kustomize.buildOptions": "--enable-alpha-plugins --enable-exec"}}'
Next, we can modify the Deployment of the ArgoCD application to add KSOPS and a modified kustomize (containing the kustomize plugin viaduct.ai/v1) via the initContainers.
Let’s create the file patch-argocd-repo-server.yaml:
# patch-argocd-repo-server.yaml
kind: Deployment
metadata:
name: argocd-repo-server
namespace: argocd
spec:
template:
spec:
initContainers:
- name: install-ksops
image: viaductoss/ksops:v4.3.1
securityContext.runAsNonRoot: true
command: ["/bin/sh", "-c"]
args:
- echo "Installing KSOPS and Kustomize...";
mv ksops /custom-tools/;
mv kustomize /custom-tools/kustomize ;
echo "Done.";
volumeMounts:
- mountPath: /custom-tools
name: custom-tools
- name: import-gpg-key
image: quay.io/argoproj/argocd:v2.10.4
command: ["gpg", "--import","/sops-gpg/sops.asc"]
env:
- name: GNUPGHOME
value: /gnupg-home/.gnupg
volumeMounts:
- mountPath: /sops-gpg
name: sops-gpg
- mountPath: /gnupg-home
name: gnupg-home
containers:
- name: argocd-repo-server
env:
- name: XDG_CONFIG_HOME
value: /.config
- name: GNUPGHOME
value: /home/argocd/.gnupg
volumeMounts:
- mountPath: /home/argocd/.gnupg
name: gnupg-home
subPath: .gnupg
- mountPath: /usr/local/bin/ksops
name: custom-tools
subPath: ksops
- mountPath: /usr/local/bin/kustomize
name: custom-tools
subPath: kustomize
volumes:
- name: custom-tools
emptyDir: {}
- name: gnupg-home
emptyDir: {}
- name: sops-gpg
secret:
secretName: sops-gpg
Let’s apply the patch directly to the deployment argocd-repo-server:
kubectl patch deployment -n argocd argocd-repo-server --patch "$(cat patch-argocd-repo-server.yaml)
The new version of the argocd-repo-server pod should be blocked pending the GPG key.
$ kubectl describe -n argocd --selector "app.kubernetes.io/name=argocd-repo-server" pods
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 10m default-scheduler Successfully assigned argocd/argocd-repo-server-586779485d-kw2j6 to rpi4-02
Warning FailedMount 108s (x12 over 10m) kubelet MountVolume.SetUp failed for volume "sops-gpg" : secret "sops-gpg" not found
Create a GPG key for KSOPS
It is possible to use a GPG key or Age to encrypt our files with SOPS (KSOPS documentation offers both cases).
For this tutorial, I will use a GPG key. I invite you to dedicate a GPG key to KSOPS/ArgoCD for security reasons.
Warning
If you already have a key but it has a password: it will not be possible to use it with KSOPS.
I will generate a GPG key with no expiration date in order to store it in a Kubernetes secret.
export GPG_NAME="argocd-key"
export GPG_COMMENT="decrypt yaml files with argocd"
gpg --batch --full-generate-key <<EOF
%no-protection
Key-Type: 1
Key-Length: 4096
Subkey-Type: 1
Subkey-Length: 4096
Expire-Date: 0
Name-Comment: ${GPG_COMMENT}
Name-Real: ${GPG_NAME}
EOF
Now let’s retrieve the GPG key ID. If you have a single key pair in your keyring, you can retrieve it directly with the following command:
GPG_ID=$(gpg --list-secret-keys --keyid-format LONG | grep sec | awk '{print $2}' | cut -d'/' -f2) # Si vous n'avez qu'une seule paire dans le trousseau
… otherwise run the command gpg --list-secret-keys and retrieve the string with the value “sec” (e.g., GPG_ID=F21681FB17B40B7FFF573EF3F300795590071418).
Using the key ID we just generated, we send it to the cluster as a secret.
gpg --export-secret-keys --armor "${GPG_ID}" |
kubectl create secret generic sops-gpg \
--namespace=argocd \
--from-file=sops.asc=/dev/stdin
Encrypting files
I will create a simple Deployment file that I will encrypt with KSOPS.
# deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: simple-coffee
labels:
app: simple-coffee
spec:
replicas: 1
selector:
matchLabels:
app: simple-coffee
template:
metadata:
labels:
app: simple-coffee
spec:
containers:
- name: nginx
image: qjoly/kubernetes-coffee-image:simple
ports:
- containerPort: 80
env:
- name: MACHINE_COFFEE
value: "Krups à grain"
I want to encrypt the “containers” part, I will create the file .sops.yaml to define the fields to encrypt and the key to use.
creation_rules:
- path_regex: sealed.yaml$
encrypted_regex: "^(containers)$"
pgp: >-
F21681FB17B40B7FFF573EF3F300795590071478
Next, I will ask sops to encrypt the file deployment.yaml with the following command: sops -i -e deployment.yaml.
Currently, our file is well encrypted but is unusable by ArgoCD which does not know how to decrypt it (nor which files are decryptable).
To address this, I will create a Kustomize file that will execute ksops on deployment.yaml. This is a syntax that ArgoCD will be able to understand (it will use the binary ksops added by our patch).
# secret-generator.yaml
apiVersion: viaduct.ai/v1
kind: ksops
metadata:
name: secret-generator
annotations:
config.kubernetes.io/function: |
exec:
path: ksops
files:
- ./deployment.yaml
The viaduct.ai/v1 API is the Kustomize plugin (already present in the kustomize binary that we retrieve from the image containing KSOPS).
Next, I add the kustomization.yaml file which specifies the nature of the secret-generator.yaml file as a “manifest generator”.
# kustomization.yaml
apiVersion: kustomize.config.k8s.io/v1beta1
kind: Kustomization
generators:
- ./secret-generator.yaml
By putting this into a Git repository and giving it to ArgoCD, it will automatically decrypt the file without requiring any manual action.
I have published my test repository on GitHub if you want to test it yourself (you will need to modify the .sops.yaml and deployment.yaml files to match your GPG key).
This method is a bit more complex than FluxCD(+sops), but the final need is met. I still note that the patch needs to be maintained to use recent versions of ArgoCD (init-pod import-gpg-key and install-ksops).
Conclusion
I am very satisfied with ArgoCD and its features. It is very easy to install and configure without neglecting the needs of advanced users.
However, there is still much to discover around ArgoCD (Matrix generator, Dynamic Cluster Distribution, User Management via SSO …).
During the first draft of this article, I was focusing on the lack of YAML file encryption (where FluxCD offers it natively). But thanks to KSOPS (Thanks Rémi ❤️), it is possible to encrypt YAML files directly in ArgoCD seamlessly.
I have no reason not to migrate to ArgoCD for my personal projects! 😄
Thank you for reading this article, I hope you enjoyed it and found it useful. Feel free to contact me if you have any questions or comments.